Artificial Intelligence
What Is Machine Learning? An Introduction

Machine Learning (ML) is the branch of Artificial Intelligence (AI) that builds systems capable of learning from a dataset without being programmed step by step for every task. These systems infer techniques and algorithms from examples, then produce predictive models and behavior patterns on new data.
ML overlaps heavily with statistics. The key difference is emphasis: statistics focuses on inference and uncertainty; ML focuses on computational complexity. Most interesting ML problems belong to the NP-complete or NP-hard class, so the discipline centers on designing tractable solutions to problems that cannot be solved optimally in reasonable time.
Two Classic Definitions
Arthur Samuel (1959): Machine Learning is a field of study that gives computers the ability to learn without being explicitly programmed.
Tom Mitchell (1998): A program learns from experience E with respect to task T and performance measure P if its performance on T, as measured by P, improves with experience E.
Regression vs. Classification
ML systems produce output in one of two forms.
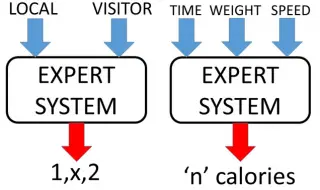
Regression maps input data to a continuous output. Both the input domain X and the output domain Y are arbitrary. A simple example is the function f: R → R that predicts calories burned given weight, run time, and speed.
Classification maps input data to a finite output set. The input domain X is arbitrary; the output Y is a small finite set such as {0, 1}, {win, draw, loss}, or {yes, no}.
After a learning phase, the trained system acts as an expert system: given new input it applies the learned function and returns a prediction, recommendation, or classification.
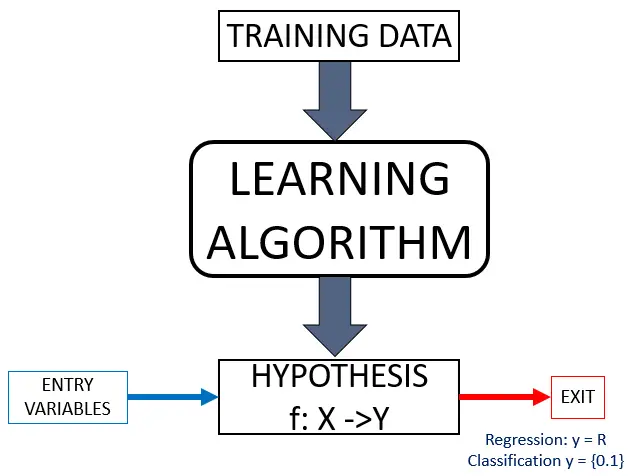
How a System Learns: The Hypothesis
Every ML system learns by finding a hypothesis (model or function) that fits a labeled training set well enough to generalize to unseen test data.
The learning goal is to minimize empirical error on training data while keeping test error low. A hypothesis that memorizes training labels exactly tends to fail on new data. A hypothesis that is too coarse misses real patterns. Finding the right balance is the central challenge.
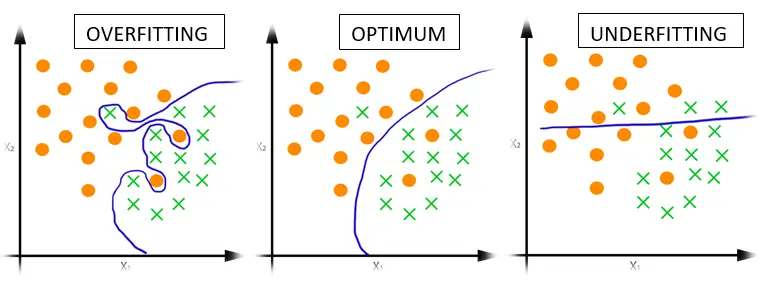
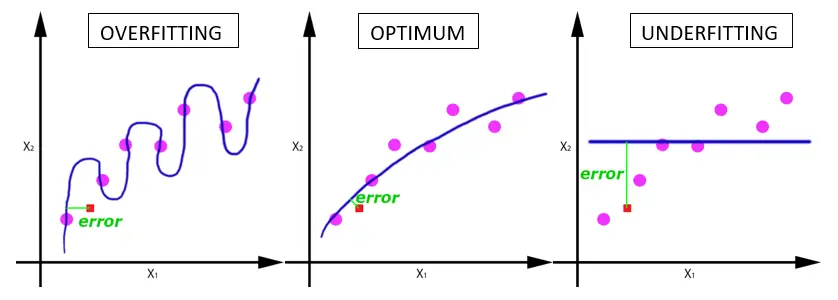
Overfitting and Underfitting
Two failure modes occur when a hypothesis does not generalize.
Overfitting happens when the hypothesis fits the training data too closely, capturing noise rather than signal. In a cricket match predictor, if the training set contains only 3 India-vs-Bangladesh matches (all Bangladesh wins), an overfitting model predicts “Bangladesh wins” even though India is historically stronger.
Underfitting happens when the hypothesis is too coarse to capture the real pattern. An underfitting model might predict “home team always wins” and fail to account for team strength at all.
Optimal generalization sits between the two: the hypothesis predicts India wins because India is one of the world’s strongest teams, it wins the majority of its matches, and home teams win about 60% of the time in the training data.
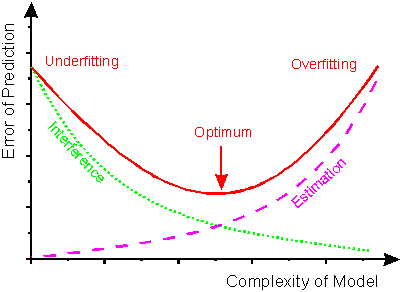
These failure modes appear visually in both classification and regression:
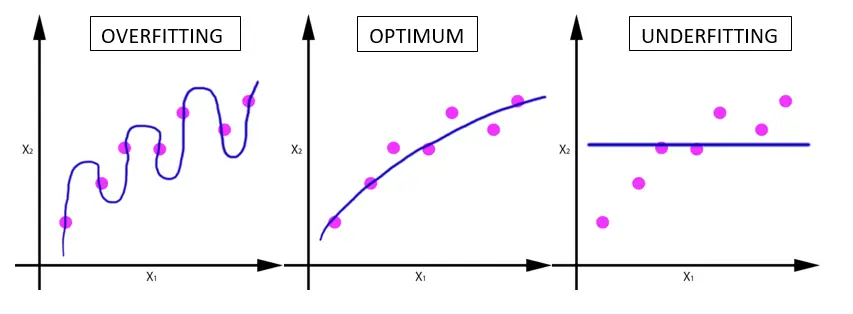
The chart below shows how test error rises at both extremes of model complexity:
6 Types of Learning
The type of available training data determines which learning approach applies.
- Supervised learning. Training data includes both input and output labels. The system learns a mapping from inputs to outputs. Produces the strongest results when labeled data is plentiful.
- Unsupervised learning. Only input data is available. The goal is to discover structure in the input domain, such as clusters or latent dimensions.
- Semi-supervised learning. A hybrid: a small labeled set combined with a large unlabeled set. Useful when labeling is expensive.
- Adaptive learning. Starts from an existing model and updates its parameters as new training data arrives, rather than learning from scratch.
- Online learning. No fixed training-then-test split. The system learns continuously during prediction, with a human validating or correcting each output in real time.
- Reinforcement learning. A hybrid of online and semi-supervised learning. Supervision is incomplete: the system receives a sparse reward signal (
{+1, -1}or{reward, penalty}) and must discover the policy that maximizes cumulative reward.
4 Evaluation Methods
After training, the hypothesis must be evaluated on held-out data. Four standard methods control how training and test sets are divided.
- Validation (resubstitution). All available data serves as both training and test. Optimistic: error is underestimated because the hypothesis is evaluated on the same data it was trained on.
- Hold-out (partition). Data is split into a training subset and a test subset. Simple, but test data is unavailable during training, which shrinks the effective training set.
- Cross-validation. Data is split into N random blocks (folds). Each fold serves as the test set once; the model is trained on the remaining N-1 folds. Test error is averaged across all N runs. Drawback: training set size drops as fold count rises.
- Leave-one-out. Each single data point serves as the test set once; the model trains on all remaining points. Equivalent to N-fold cross-validation where N equals the dataset size. Computationally expensive for large datasets.
ML Techniques and Problem Categories
Classifying ML techniques by the problem they address:
| Problem type | Supervised methods | Clustering methods |
|---|---|---|
| Classification Clustering Regression Anomaly detection Association rules Reinforcement learning Structured prediction Feature engineering Feature learning Online learning Semi-supervised learning Unsupervised learning Learning to rank Grammar induction | Decision trees Ensembles (Bagging, Boosting, Random Forest) k-NN Linear regression Naive Bayes Neural networks Logistic regression Perceptron Relevance vector machine (RVM) Support vector machine (SVM) | BIRCH Hierarchical K-means Expectation-maximization (EM) DBSCAN OPTICS Mean-shift |
| Dimensionality reduction | Probabilistic models | Anomaly detection |
|---|---|---|
| Factor analysis Canonical correlation (CCA) Independent component analysis (ICA) Linear discriminant analysis (LDA) Non-negative matrix factorization (NMF) Principal component analysis (PCA) t-distributed stochastic neighbor embedding (t-SNE) | Probabilistic graphical models (PGM) Bayesian networks Conditional random field (CRF) Hidden Markov model (HMM) | k-nearest neighbors (k-NN) Local outlier factor |
| Neural networks | Recommendation systems | Theoretical frameworks |
|---|---|---|
| Deep learning Multilayer perceptron Recurrent neural network (RNN) Restricted Boltzmann machine Self-organizing map (SOM) Convolutional neural network (CNN) | k-nearest neighbors (k-NN) Singular value decomposition (SVD) Latent semantic indexing (LSI) Probabilistic latent semantic indexing (PLSI) Latent Dirichlet allocation (LDA) | Bias-variance trade-off Computational learning theory Empirical risk minimization Occam learning PAC learning Statistical learning theory VC theory |
Further Reading
For hands-on practice, the Stanford open classroom ML course and the Caltech video library both cover the fundamentals in depth. Tom Mitchell’s textbook Machine Learning (McGraw-Hill) remains a clear reference for the theory above.
If you are working through a course that includes ML assignments and need support, GeeksProgramming has worked on ML projects since 2014. See the Machine Learning Assignment Help page for details on how submissions work. For a practical Python walkthrough of scikit-learn, neural networks, and CNNs applied to these same concepts, read Machine Learning with Python: A Practical Guide.
Related articles
-
 Machine Learning
Machine LearningBuild a Movie Recommendation System in Python
Build a movie recommender in Python with content-based filtering, collaborative filtering, and a hybrid model, then evaluate it and ship it with Flask.
Jan 27, 2025
-
 Java
JavaBus Ticketing System in Java Assignment
Bus ticketing system in Java, built from the assignment spec. 4 classes, seat grid, invoices, ban set, plus 3 bugs that erase saved data.
Jul 28, 2026
-
 Programming Homework Tips
Programming Homework TipsHow to Break Down a Programming Assignment
Learn how to turn a programming assignment brief into a clear plan using requirements, pseudocode, testing, and a C salary-raise example.
Jul 21, 2026