
Imagine this: you’re ordering your favorite pizza, and you have a specific craving for a slice of the cheesiest, pepperoni-laden delight. But instead of just asking for that one perfect slice, you’re handed the entire pizza, along with every other topping and variation imaginable. That’s what traditional APIs often feel like – an overwhelming buffet of data, where you need to sift through it all to find what you truly desire.
But what if there was a way to request exactly what you wanted, and nothing more? Enter GraphQL, the under-credited hero of modern web development. It’s like having a direct line to your data, where you call the shots. No more over-fetching or under-fetching; just the precise information you need, neatly packaged and delivered.
In this blog post, we’re diving deep into the world of GraphQL. This underappreciated gem is making waves in the web development realm, and we’re here to uncover its mysteries. Whether you’re a seasoned developer or just starting your coding journey, GraphQL has something to offer. So, let’s begin this journey of discovery and find out how GraphQL is shaping the future of web API design.
What is GraphQL?
GraphQL, which stands for “Graph Query Language,” is an innovative and versatile technology developed by Facebook in 2012 and later released as an open-source project in 2015. It’s not just an API but a comprehensive query language for your APIs, enabling you to request precisely the data you need from a server.
The core idea behind GraphQL is to provide a more efficient and flexible alternative to the traditional RESTful APIs. In REST, you typically have predefined endpoints that return fixed data structures. These endpoints may either provide too much information or not enough, leading to over-fetching or under-fetching of data. GraphQL, on the other hand, allows you to request only the data you want, eliminating the need for multiple endpoints and unnecessary data retrieval.
One of the fundamental distinctions between GraphQL and REST is the way data is requested. In REST, you have a fixed set of endpoints for different resources, and the server determines the structure of the response. With GraphQL, clients specify their data requirements in the form of queries, and the server responds with the requested data in the exact structure specified. This means no more fetching extra data or making multiple requests to different endpoints to assemble the required information.
GraphQL was conceived as a solution to address some key limitations of REST APIs. As web applications grew more complex and the demand for tailored data increased, RESTful APIs struggled to keep up. Developers often found themselves either overloading the server with redundant data or facing issues with under-fetching, which led to additional requests and slower loading times.
Key Concepts
To truly understand GraphQL, we need to understand some key concepts, which form the foundation of this powerful query language.
Schema
At the core of GraphQL is the schema. Think of this as a blueprint that defines the structure of your data. The schema serves as a contract between the client and the server. It specifies the types of data that can be requested and how they are related. In essence, it outlines the capabilities of your GraphQL API, making it crystal clear what data is available and how to access it.
Types
GraphQL categorizes data into various types. These include scalar types, object types, and custom types. Scalar types represent individual values like integers, strings, and booleans. Object types define complex data structures, essentially grouping related fields together. Custom types allow you to define your data structures, enabling you to create APIs tailored to your specific needs.
Queries and Mutations
Queries and mutations are two fundamental operations in GraphQL. Queries are used to request data from the server. You specify what data you want, and the server responds with that exact data structure. Mutations, on the other hand, allow you to modify data on the server. You can add, update, or delete records as needed, providing a powerful means to interact with your data source.
Fragments
Fragments are a clever feature in GraphQL that simplifies query writing. They allow you to define reusable pieces of a query that can be included in multiple queries. This not only keeps your code DRY (Don’t Repeat Yourself) but also ensures consistency across your API requests.
Resolvers
Resolvers are the bridge between your GraphQL server and your data source. They are responsible for fetching the actual data in response to a query. Each field in your schema has a corresponding resolver that knows how to retrieve the data for that field. This separation of concerns makes your GraphQL server highly flexible and allows you to connect to various data sources, be it a database, an external API, or any other data store.

Schema Definition Language (SDL)
The SDL is a powerful tool used to define your GraphQL schema. It’s a clear and concise way to lay out your data structure, making it easy for both developers and machines to understand the schema’s architecture. This human-readable syntax is one of the reasons why GraphQL is so developer-friendly.
The SDL plays a crucial role in creating a shared understanding between client and server. By using the SDL, you establish a contract, and everyone knows what to expect. This contract defines the types of data you can request, the queries you can make, and the mutations you can perform.
With SDL, you can explicitly define the types in your schema. Scalar types like Int, String, and Boolean are built-in, but you can create custom types to represent more complex data structures. For example, you can define an “Author” type with fields like “name” and “books,” and a “Book” type with fields such as “title” and “author.”
Queries and mutations are also defined using SDL. You specify what data you can request with queries and how you can change it with mutations. For instance, you can define a “query” called “getAuthor” that takes an argument for the author’s name and returns the author’s details.
Here’s a simple SDL example:
type Author {
name: String!
books: [Book!]!
}
type Book {
title: String!
author: Author!
}
type Query {
getAuthor(name: String!): Author
}
In this example, we’ve defined two custom types, “Author” and “Book,” along with a query named “getAuthor.”
Building GraphQL Server
There’s a vast and diverse ecosystem of tools and frameworks to choose from when building your GraphQL server. Some popular options include Apollo Server, Express.js, Django, and more. These tools provide a foundation to make the server setup smoother and help handle various aspects of your GraphQL implementation.
- Apollo Server: A community-driven open-source GraphQL server that works seamlessly with Apollo Client. It’s a fantastic choice if you’re looking for a GraphQL-first approach.
- Express.js: A robust web application framework for Node.js that’s incredibly versatile and can be extended with GraphQL using libraries like express-graphql.
- Django: If you’re working with Python, Django has a package called Graphene-Django that makes integrating GraphQL into your Django application straightforward.
While the specific steps may vary depending on the tools and frameworks you choose, here’s a general outline of what setting up a simple GraphQL server involves:
- Create a New Project: Set up a new project directory and initialize it with the necessary package manager for your chosen environment (e.g., npm for Node.js or pip for Python).
- Install Dependencies: Install the required packages, including your chosen GraphQL server library and any additional tools or middleware you might need.
- Define Your Schema: Use the Schema Definition Language (SDL) to define your GraphQL schema. This schema will outline your data types, queries, and mutations.
- Implement Resolvers: Write resolver functions for each field in your schema. Resolvers are responsible for fetching the data in response to a query.
- Create Your Server: Set up a server using your chosen framework or tool. Define a single route that listens for incoming GraphQL requests.
- Connect Schema and Resolvers: Connect your schema and resolver functions to your server, allowing it to handle incoming GraphQL queries and mutations.
- Start the Server: Launch your server, and it should be ready to accept GraphQL queries.
The beauty of GraphQL is that you can get a simple server up and running relatively quickly, and you have the flexibility to expand and refine it as your project evolves.
Writing GraphQL Queries
Now that you’ve got your GraphQL server up and running, it’s time to explore the art of writing GraphQL queries.
Requesting Specific Data
The fundamental building block of a GraphQL query is the selection set. In a query, you specify the fields you want to retrieve, and the server responds with the requested data. For example, if you’re fetching information about an author, your query might look like this:
```(GraphQL)
{
author(id: 1) {
name
books {
title
}
}
}
In this query, we’re asking for the “name” of the author with ID 1 and the “title” of all their “books.” Nothing more, nothing less.
Query Parameters and Arguments
Queries can also accept parameters, which are like function arguments. They allow you to make your queries dynamic. For instance, in the query above, we used the “id” parameter to specify the author’s ID we want to fetch.
Aliases for Clarity
Sometimes, you might want to request the same field with different arguments. Aliases come in handy here. They enable you to rename the fields in the response to avoid confusion. Here’s an example:
{
firstAuthor: author(id: 1) {
name
}
secondAuthor: author(id: 2) {
name
}
}
Fragments: Reusing Query Parts
As your queries grow, you’ll often find yourself repeating similar structures. This is where fragments become invaluable. You can define a fragment once and then include it in multiple queries. This keeps your code DRY (Don’t Repeat Yourself) and ensures consistency.
fragment AuthorInfo on Author {
name
books {
title
}
}
{
firstAuthor: author(id: 1) {
…AuthorInfo
}
secondAuthor: author(id: 2) {
…AuthorInfo
}
}
Common Query Patterns
GraphQL offers several common query patterns to make your life easier:
- Queries on Multiple Types: You can query multiple types in a single request.
- Nested Queries: Fetching data from related objects with nested queries.
- Pagination: Implementing pagination to limit the number of results returned.
- Filtering and Sorting: Using arguments to filter and sort data.

Mutations in GraphQL
Up until now, we’ve been discussing how to retrieve data with GraphQL queries. But what if you want to change that data? That’s where mutations come into play. A mutation is a GraphQL operation designed for altering data. Whether you need to add a new record, update an existing one, or delete data, mutations provide a structured and efficient way to do it.
Each mutation defines an input type, specifying the data you need to provide when making the mutation. Additionally, it declares a return type, indicating what data you’ll receive as a response after the mutation is executed. This clear separation of input and return types ensures that mutations are self-contained and predictable.
Let’s look at a few common mutation examples to illustrate how they work:
Adding Data
Suppose you want to add a new book to your library. You’d create a mutation like this:
mutation {
addBook(title: “New Book Title”, author: “Author Name”) {
id
title
author
}
}
This mutation receives the title and author as input and returns the newly added book’s ID, title, and author.
Updating Data
To update an existing author’s name, you might use a mutation like this:
mutation {
updateAuthor(id: 1, name: “New Author Name”) {
id
name
}
}
Here, you provide the author’s ID and the updated name, and the mutation returns the author’s ID and the modified name.
Deleting Data
If you want to remove a book from your library, you’d have a mutation like this
mutation {
deleteBook(id: 123) {
id
title
author
}
}
The mutation requires the book’s ID to be deleted and returns the ID, title, and author of the deleted book.
GraphQL Best Practices
It is essential to understand some best practices that will help you design efficient, secure, and robust APIs.
Designing Efficient Schemas: Efficiency begins with a well-crafted schema. When designing your schema, strive for simplicity and consistency. Keep your types and fields concise and avoid unnecessary complexity. Remember, the more straightforward your schema, the easier it is for clients to understand and use.
Handling Authentication and Authorization: Security is a top concern when it comes to APIs. GraphQL allows for fine-grained control over authentication and authorization. You can use middleware or custom resolvers to implement authentication and ensure that only authorized users can access specific data or perform certain mutations. Make use of role-based access control to define who can do what within your API.
Error Handling and Response Structure: Handling errors gracefully is a must for any API. GraphQL provides a structured way to return errors alongside your data. Always ensure that your responses include an “errors” field that provides details about any issues. Additionally, return meaningful HTTP status codes to signal the result of the request.
{
“data”: {
“author”: {
“name”: “John Doe”
},
“book”: null
},
“errors”: [
{
“message”: “Book not found”,
“path”: [“book”]
}
]
}
By structuring your responses in this manner, clients can easily identify what went wrong and why, making debugging and troubleshooting more manageable.
Optimizing Query Performance: Efficient queries are crucial for maintaining a responsive API. Avoid N+1 query problems by using batch loading techniques or data loader libraries. Limit the depth of nested queries to prevent overly complex and resource-intensive requests.
Real-world Use Cases
GraphQL has made a significant impact across various industries, and companies worldwide are reaping the benefits of its flexibility and precision.
In Various Industries and Applications
Social Media: Platforms like Facebook, which introduced GraphQL, rely on it for their API services. It allows users to retrieve personalized data efficiently, such as posts, comments, and media.
E-commerce: E-commerce giants like Shopify use GraphQL to provide tailored shopping experiences. It enables users to query specific product information, prices, and inventory levels with ease.
Travel: Travel companies employ GraphQL to offer dynamic flight and hotel search, allowing users to fetch precisely the travel data they need, like available flights, prices, and accommodations.
Healthcare: The healthcare sector uses GraphQL to access patient records securely. It allows medical professionals to retrieve and update patient data efficiently.
Gaming: Online gaming platforms leverage GraphQL to provide real-time game statistics and leaderboards, catering to gamers’ unique queries and requests.
Let’s see some real-world case studies that showcase the tangible benefits of GraphQL:
GitHub: GitHub, the world’s leading software development platform, adopted GraphQL to enhance its API performance and flexibility. This move has allowed developers to fetch only the data they need, reducing the complexity of API responses.
Twitter: Twitter used GraphQL to create its “Ads API” for advertisers. GraphQL’s ability to request specific data has made it easier for advertisers to retrieve campaign information, enhancing their experience on the platform.
The New York Times: The New York Times implemented GraphQL to optimize the content delivery to its readers. GraphQL’s efficiency enables personalized article recommendations and streamlined content distribution.
These case studies illustrate how GraphQL has been harnessed to improve data fetching, enhance user experiences, and simplify complex data access across various domains
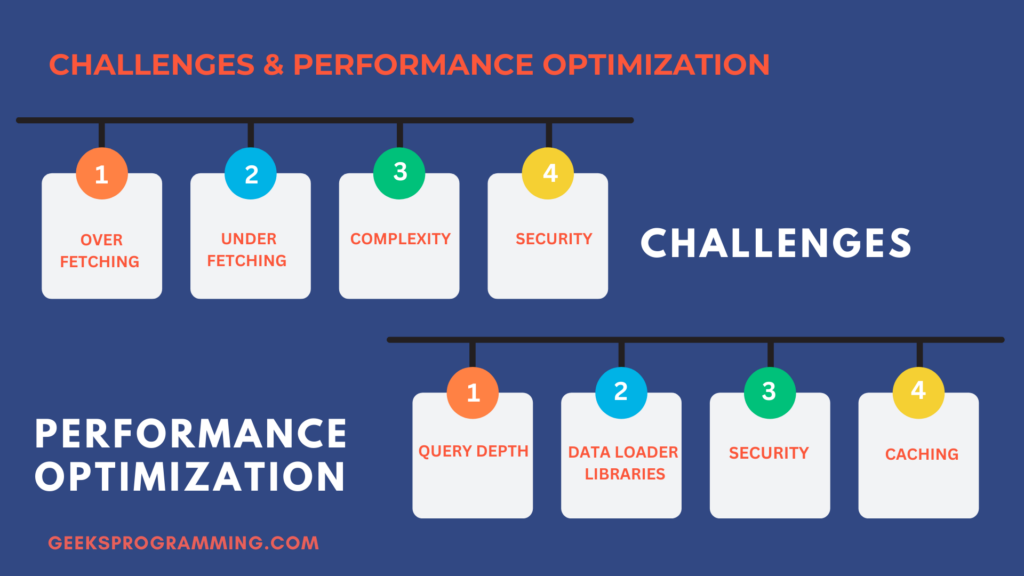
Challenges and Considerations
While GraphQL offers a world of advantages, it’s important to be aware of the challenges and considerations that can arise when working with this technology.
Common Challenges and Limitations
- Over-fetching and Under-fetching: As GraphQL gives clients the power to request data precisely, it’s possible for clients to over-fetch data (asking for more than needed) or under-fetch data (not requesting necessary information).
- Complexity: Complex queries can lead to performance issues, as fetching nested and interrelated data can be resource-intensive.
- Security: Care must be taken to ensure that your GraphQL server is protected from malicious queries, as poorly designed schemas can expose sensitive data.
Performance Optimization
To address these challenges and ensure optimal performance:
- Query Depth and Complexity Limitation: You can set a depth and complexity limit for queries to prevent excessively complex requests. This mitigates potential performance bottlenecks.
- Data Loader Libraries: Use data loader libraries to batch and optimize database queries. These libraries help prevent the N+1 query problem and improve query efficiency.
- Caching: Implement query caching to reduce the load on your data source and expedite response times for frequently requested data.
- Throttling and Rate Limiting: Apply throttling and rate limiting to control the number and frequency of incoming requests, preventing potential abuse or overuse of resources.
Understanding the challenges and being proactive in optimizing the performance of your GraphQL server can help you make the most of this powerful technology while ensuring a smooth and responsive user experience.
Comparison with REST and other APIs
Advantages of GraphQL
- Efficiency: GraphQL allows clients to request only the data they need, eliminating over-fetching and under-fetching of data. This means faster and more efficient data retrieval.
- Flexibility: Unlike REST, where you’re constrained by predefined endpoints, GraphQL provides the flexibility to define the structure of the response, enabling clients to shape their queries.
- Versioning: GraphQL’s schema evolution allows you to add new features without breaking existing clients. This is a significant improvement over traditional REST versioning.
- Single Endpoint: In REST, you typically have multiple endpoints for different resources. GraphQL consolidates all these into a single endpoint, simplifying API management.
Disadvantages of GraphQL
- Complexity: The flexibility of GraphQL can lead to complex queries if not managed properly. This complexity can impact server performance.
- Learning Curve: For newcomers, GraphQL may have a steeper learning curve compared to REST.
While REST is excellent for simple, read-only APIs, GraphQL shines in situations where flexibility, efficiency, and precise data retrieval are required. It’s particularly beneficial for applications with complex data requirements or those that need real-time updates. Other API technologies, like gRPC, are suitable for specific use cases, such as microservices communication.
Conclusion
In conclusion, GraphQL is a game-changer in the world of web development, offering a dynamic and efficient approach to data retrieval and modification. With its ability to empower clients, eliminate data over-fetching, and provide a structured way to shape queries, GraphQL has quickly become the go-to choice for modern APIs.
As we’ve explored its core concepts, schema definition, query and mutation writing, and best practices, you’ve hopefully now gained a strong foundation to go about on your GraphQL journey. We’ve discussed its practical applications across various industries and the benefits it brings to real-world scenarios.
While GraphQL isn’t without its challenges, such as query complexity, it’s a technology well worth mastering. It is ensured that GraphQL will continue to be a valuable tool, streamlining data interactions and ensuring that one gets precisely the information they need.
So, I hope that you find GraphQL not just intriguing, but truly transformative. I encourage you to explore further, practice, and integrate it into your future projects. Whether you’re developing the next big thing in social media, e-commerce, healthcare, or any other domain, GraphQL can help you build responsive, user-centric applications that stand out in an increasingly competitive digital world. Happy coding!


